Object Detection의 핵심 Region Proposal 총 정리

Region Proposal은 이미지 내에서 물체가 있을 것으로 추정되는 영역을 찾아내는 작업입니다. 이는 Object Detection의 핵심이며, 이를 통해 물체의 위치를 찾아내고 분류하는 작업을 수행할 수 있습니다.
CNN을 기반으로 하는 이미지 분류 모델에 대해 학습해봤다면 이것이 어떻게 Object Detection으로 확장되는지에 대해 궁금해질 수 있습니다. 이번 포스팅에서는 Region Proposal에 대해 알아보겠습니다.
과거의 Region Proposal은 알고리즘이었다.
Object Detection의 초기에는 이미지에서 영역을 찾아내는 작업을 알고리즘으로 구현했습니다.
Sliding Window

아주 초기에는 Sliding Window 방식을 사용했는데, 사각형의 window를 이미지 위에서 이동시키며 각 window에 대해 이미지 분류 모델로 객체가 있는지 판단하는 방식입니다. 상당히 많은 window를 검사해야 하기 때문에 속도가 느리고, 다양한 크기와 비율을 가진 물체를 찾아내기에 한계가 있었습니다.
Selective Search

Sliding Window보다 훨씬 더 나은 방법으로 Selective Search가 등장합니다. 여러 단계의 segmentation으로 영역을 형성하며 객체 후보를 찾아내는 방식입니다. Selective Search는 R-CNN과 Fast R-CNN의 region proposal로 활용되었습니다.
분야에 특화된 알고리즘 구현
이 외에도 여러 알고리즘이 존재합니다. Edge Boxes의 경우 테두리를 찾아내는 방식으로 Selective Search보다 정확도는 떨어지지만 속도가 빠르다는 장점이 있습니다. CCTV와 같은 분야에서는 Blob 단위로 배경을 미리 학습하여 배경과 달라지는 영역을 객체로 판단하는 경우도 있었습니다. 이와 같이 각 분야에 특화된 알고리즘을 직접 구현하기도 했습니다.
학습 가능한 Region Proposal의 등장
Object Detection의 연구가 진행되면서 region proposal 수행 방식에 대한 패러다임 전환이 일어납니다. 직접 구현하는 알고리즘에서 학습 가능한 딥러닝으로의 전환입니다. 이제는 라벨링된 bounding box 데이터만 존재한다면 region proposal 학습이 가능해졌습니다.
RPN (Region Proposal Network)
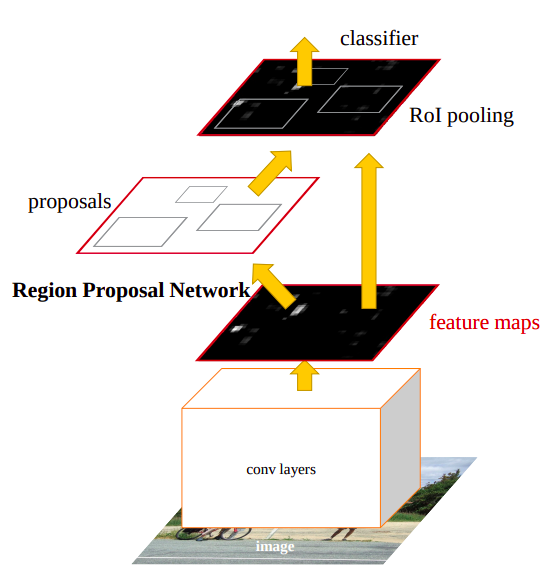
Faster R-CNN에 처음 도입된 RPN(Region Proposal Network)은 처음으로 학습 가능한 Region Proposal을 제안했으며, 이후에 등장하는 Object Detection 모델에 많은 영향을 끼쳤습니다. RPN은 feature map을 입력으로 받아 영역 후보들의 위치와 크기를 나타내는 x center, y center, width, height 값과 배경 또는 객체인지에 대한 확률 score 값을 반환합니다.
Feature map이란 convolutional layer의 출력값으로, 이미지의 특징을 담고있는 텐서입니다. 여러 convolutional layer를 거치면서 downsampling이 되는 것이 특징입니다. 예를 들어 input이 224x224일때 마지막 feature map에서는 7x7이 될 수 있습니다. 보통 마지막 feature map을 사용하지만, SSD와 같은 다른 일부 모델은 중간 feature map까지 사용하기도 합니다.
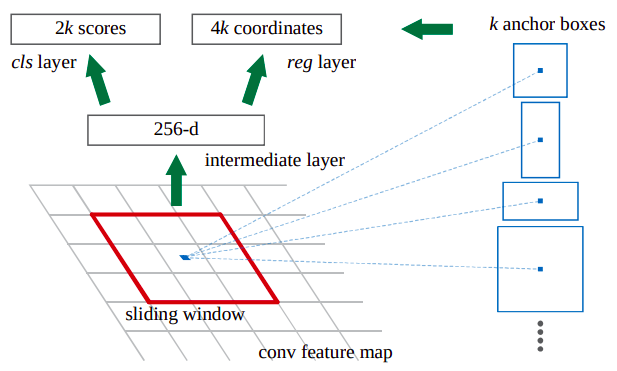
RPN은 feature map 위치별로 bounding box 후보를 예측합니다. 각 위치별로 $k$개의 bounding box 후보를 예측할때, 각 후보별로 2개의 score값(배경 또는 객체일 확률)과 4개의 좌표값(x center, y center, width, height)을 예측하여 총 $6 \cdot k$개의 값을 예측합니다. 거기에 feature map의 넓이 $w$와 높이 $h$를 반영하여, 하나의 이미지를 input으로 받았을때 총 $w \cdot h \cdot k \cdot 6$개의 값을 반환합니다.
RPN을 사용한다는 것은 Two-Stage Detector라는 것을 의미합니다. 즉, Region Proposal과 Classification을 따로 수행하는 방식입니다. RPN을 통해 추출된 모든 후보 영역 중 이미지의 객체를을 가장 잘 대표하는 영역들만 선택하여 classification layer로 보냅니다.
One-Stage Detector
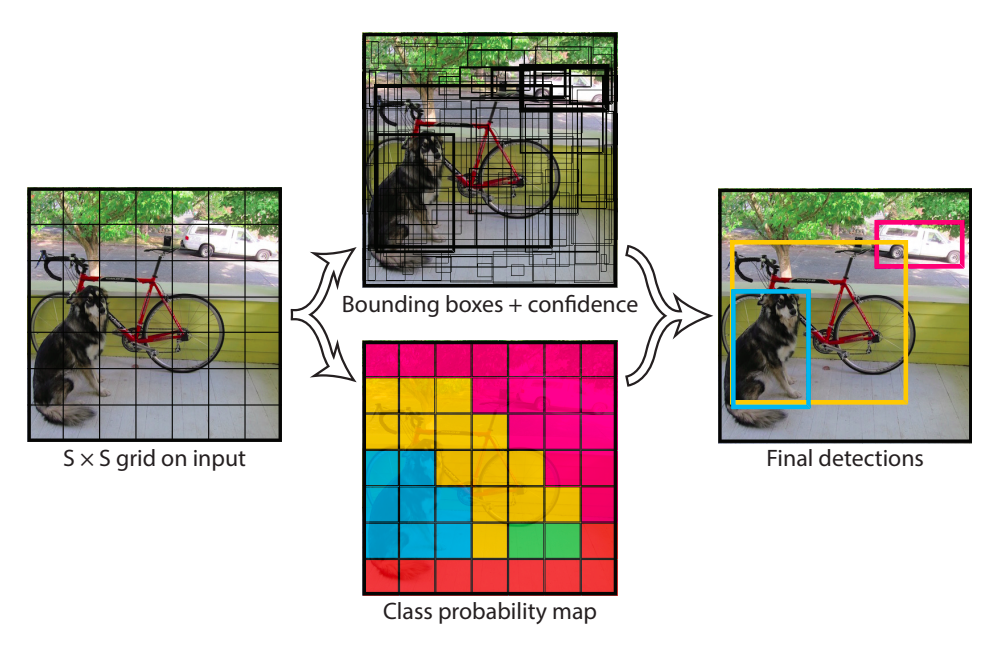
One-stage detector의 region proposal 방식은 RPN의 영향을 받아 feature map의 위치별로 bounding box 후보를 예측한다는 측면에서는 동일합니다. 그러나 one-stage detector에는 region proposal과 classification을 따로 구분하지 않고, 하나의 network로 묶어서 학습합니다. 그렇기에 RPN과 같이 region proposal만을 수행하는 network 명칭이 따로 존재하지 않습니다.
One-stage detector는 영역 후보와 더불어 그 후보의 class까지 미리 예측합니다. 위 사진에 해당되는 YOLOv1은 feature map 위치별로 classification을 하여 같은 feature map 위치에서 예측된 후보들은 전부 같은 class로 추정됩니다. 이후에 나온 모델에서는 bounding box 후보별로 classification을 하여 같은 feature map이어도 다른 class를 가질 수 있습니다.
One-stage detector에서는 각 bounding box 정보 5개(x center, y center, width, height, score), 그리고 각 class에 대한 확률 score를 예측합니다. feature map의 각 위치별로 $k$개의 bounding box 후보를 예측하고 $c$개의 class를 예측한다고 했을때 feature map 위치별 classification의 경우 총 $5 \cdot k+c$개, bounding box별 classification의 경우 총 $k \cdot (5+c)$개의 값을 반환합니다. 거기에 feature map의 넓이 $w$와 높이 $h$를 반영하여, 하나의 이미지를 input으로 받았을때 반환할 값의 총 갯수는 $w \cdot h \cdot ( 5 \cdot k+c )$ 또는 $w \cdot h \cdot k \cdot (5+c)$개까지 될 수 있습니다.
Two-stage detector에 비해 상당히 많은 값을 반환하지만 classification layer가 따로 존재하지 않아서 속도는 오히려 더 빠릅니다. 그렇기에 one-stage detector가 더 많이 연구되는 추세가 이어지고 있습니다.
Region Proposal에 사용되는 기법들
IOU (Intersection over Union)
$\text{IOU}$는 두 영역의 겹치는 정도를 나타내는 지표로, 두 영역을 $A$와 $B$라고 할 때 다음과 같이 정의됩니다.
$$ \text{IOU} = \frac{A \cap B}{A \cup B} $$
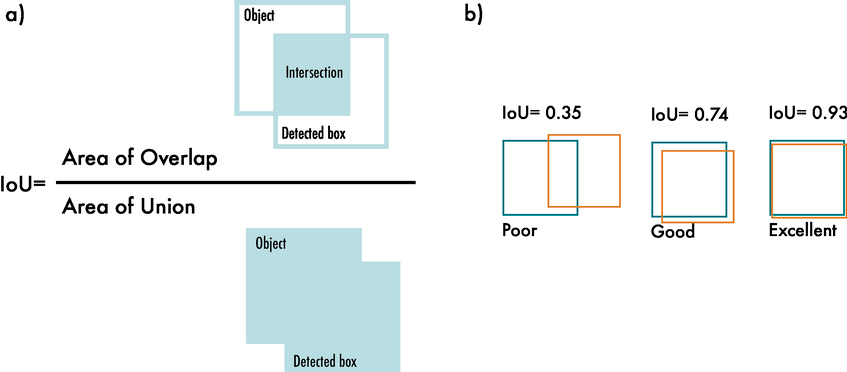
$0$(겹치는 부분이 없음)에서 $1$(완전히 겹침) 사이의 값을 가지며, 예측된 bounding box가 실제 bounding box와 얼마나 일치하는지를 나타내는 지표가 되기도 하여, loss 함수로 활용될 수 있습니다.
Anchor Box
Anchor box는 미리 정의된 bounding box의 크기와 비율로, 다양한 크기와 비율의 객체를 탐지하기 위해 고안된 개념입니다. Anchor box는 feature map의 각 위치별로 존재합니다. $1:1$, $1:2$, $2:1$의 3개의 비율을 3개의 크기를 사용한다면 각 위치별로 9개의 anchor box가 존재하게 됩니다.
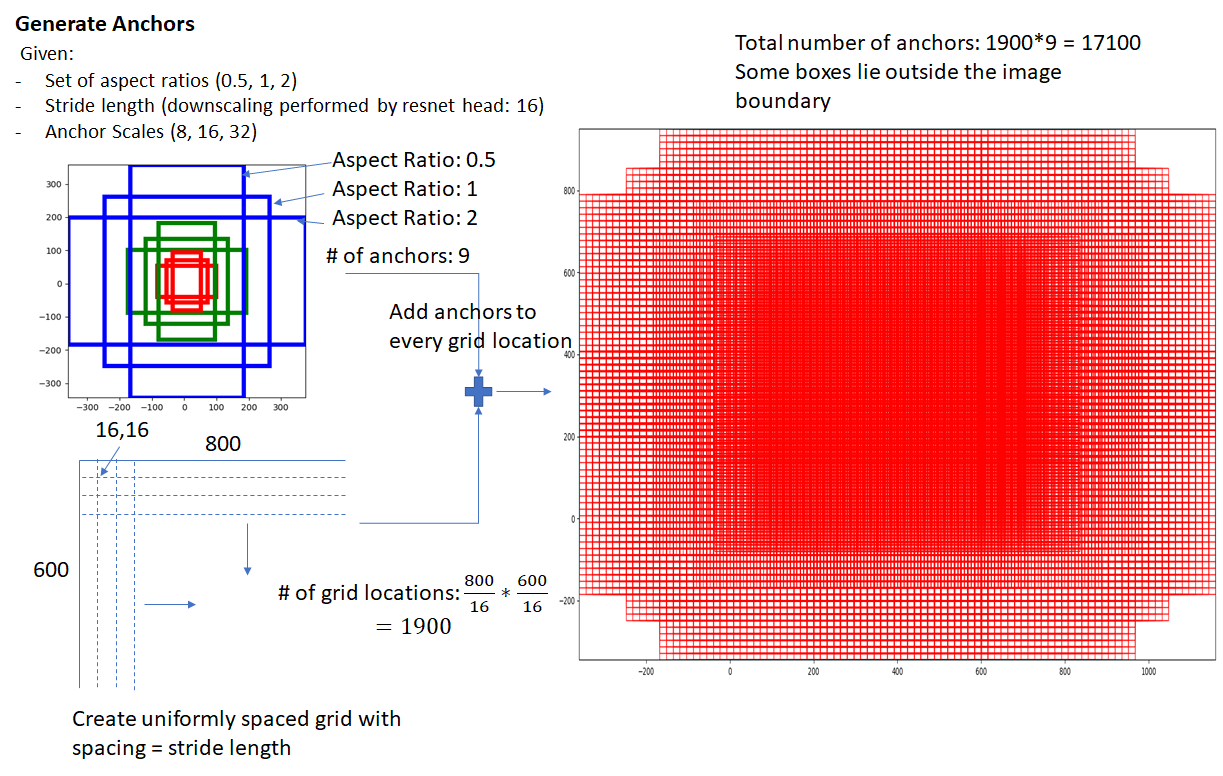
Anchor box를 사용한다고 해서 정해진 크기와 비율의 객체만 탐지하는 것은 아닙니다. 크기와 비율 별로 분리하여 학습을 하기 위한 도구일 뿐, 실제 예측이 정해진 bounding box만으로 제한되지는 않습니다.
Anchor box의 trade-off
Anchor box는 같은 feature map 위치에 다른 크기와 비율의 bounding box가 존재할 수 있음을 반영하여 성능을 향상시킵니다. 대표적으로 Faster R-CNN과 SSD에서 anchor box가 사용됩니다. YOLO 초기 버전은 anchor box를 사용하지 않았다가 YOLOv2에서 도입되었습니다.
그러나 anchor box로 인해 bounding box 후보의 수가 상당히 많이 늘어나게 됩니다. Anchor box가 성능 지표를 위해 활용되는 benchmark 데이터셋에서는 성능 향상에 있어서 중요할지 모르겠으나 실제 적용에서는 계산량만 많아지고 성능에 큰 영향을 미치지 않을 수 있습니다. 따라서 YOLO의 최신 버전에서는 anchor box를 사용하지 않는 방향으로 발전하고 있습니다.
Anchor Box를 활용한 모델 학습
Anchor box를 활용하는 모델은 anchor box 갯수 만큼의 bounding box 후보를 예측합니다. Ground truth 영역에 대해 anchor box와의 $\text{IOU}$를 계산하고, $\text{IOU}$가 일정 수치 (일반적으로 $0.7$) 이상인 anchor box에 해당되는 영역에 대해서 positive learning을, 일정 수치 (일반적으로 $0.3$) 이하인 anchor box에 해당되는 영역에 대해서 negative learning을 수행합니다.
NMS (Non-Maximum Suppression)

Region proposal 수행 결과를 score로 걸러낸다 하더라도 상당히 많은 bounding box가 예측됩니다. 잘 학습된 모델이라면 객체를 포함하는 여러 bounding box가 겹쳐지는 형태가 될것입니다. 이때 NMS가 활용됩니다.
NMS는 중복된 bounding box를 제거하는 알고리즘입니다. 여러 bounding box 후보 중 가장 확률이 높은 bounding box를 선택하고, $\text{IOU}$가 일정 이상인 bounding box를 제거하는 방식으로 동작합니다.
Two-stage detector에서는 RPN에서 추출된 bounding box 후보들을 NMS로 걸러낸 후 classification layer로 보내지고, one-stage detector에서는 최종 결과에서 NMS를 수행합니다.


댓글남기기