Transformer 모델의 아키텍처와 핵심 개념
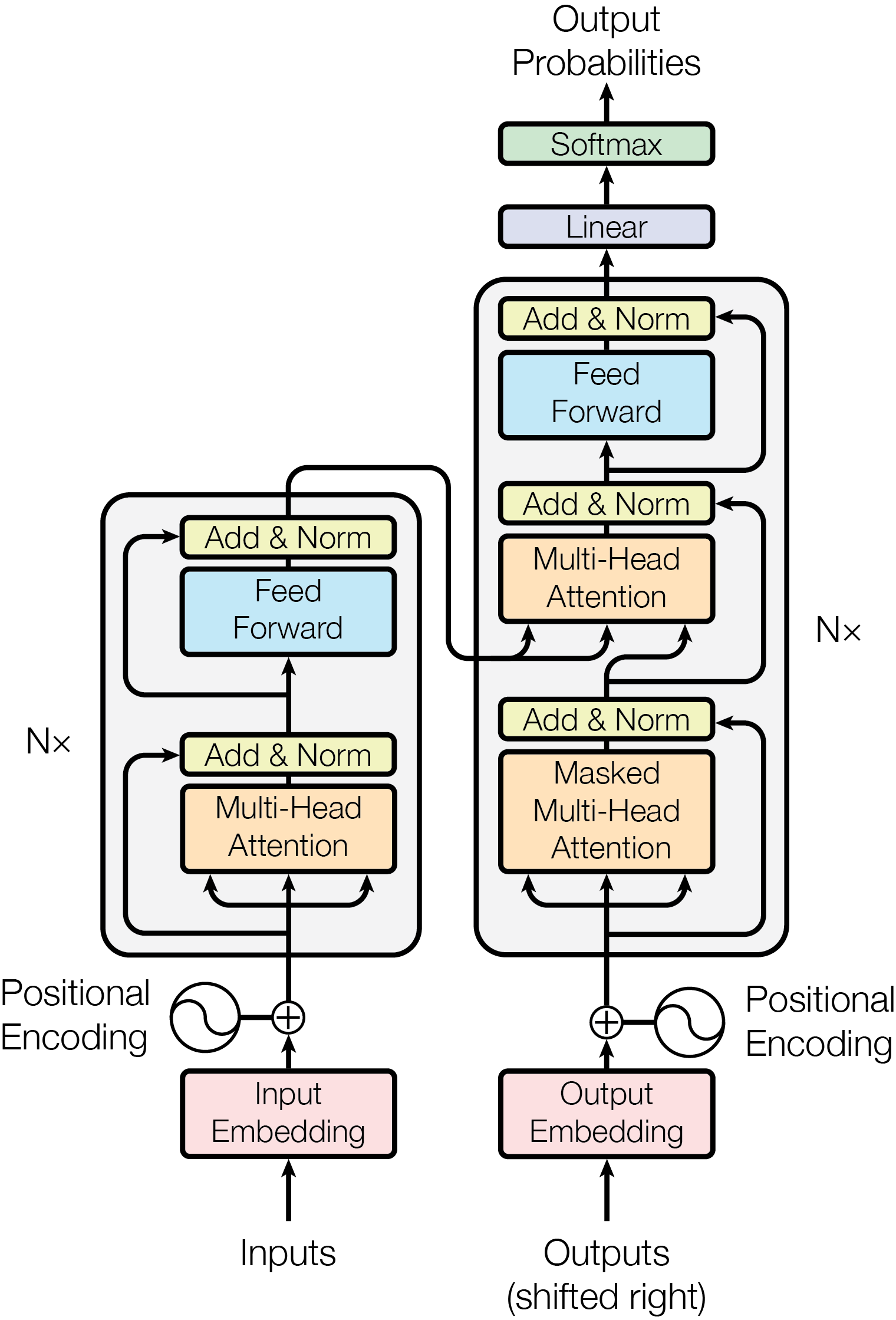
Transformer 모델의 등장 이후 자연어 처리 분야는 급격한 발전을 이루었습니다. 기존 자연어 처리 모델이 가진 한계점을 극복하면서 Transformer는 LLM의 핵심 아키텍처로 자리 잡게 되었습니다.
Transformer 모델로 인해 LLM 분야는 더 좋은 아키텍처를 찾는 경쟁에서 더 큰 모델을 만드는 경쟁으로 넘어갔습니다. 이에 따라 하드웨어 자원과 연산량이 모델의 성능을 결정하는 중요한 요소가 되었으며, 이는 반도체 및 에너지 산업에도 큰 영향을 미치고 있습니다. LLM 분야의 중심이 된 Transformer 모델의 아키텍처와 핵심 개념에 대해 자세히 살펴보도록 하겠습니다.
자연어 처리 모델의 핵심 요소
Transformer 아키텍처의 탄생 배경을 이해하기 위해 자연어 처리 모델의 핵심 요소를 살펴봅시다.
Word Embedding
텍스트를 수치적 표현으로 나타내는 방법이 필요합니다. 단어별로 분리하고, 각 단어를 벡터로 표현하는 방법을 생각해 볼 수 있습니다. 텍스트를 단어별로 분리하는 것을 토큰화(tokenization)라고 부르며, 각 토큰의 벡터 변환을 word embedding이라고 부릅니다.
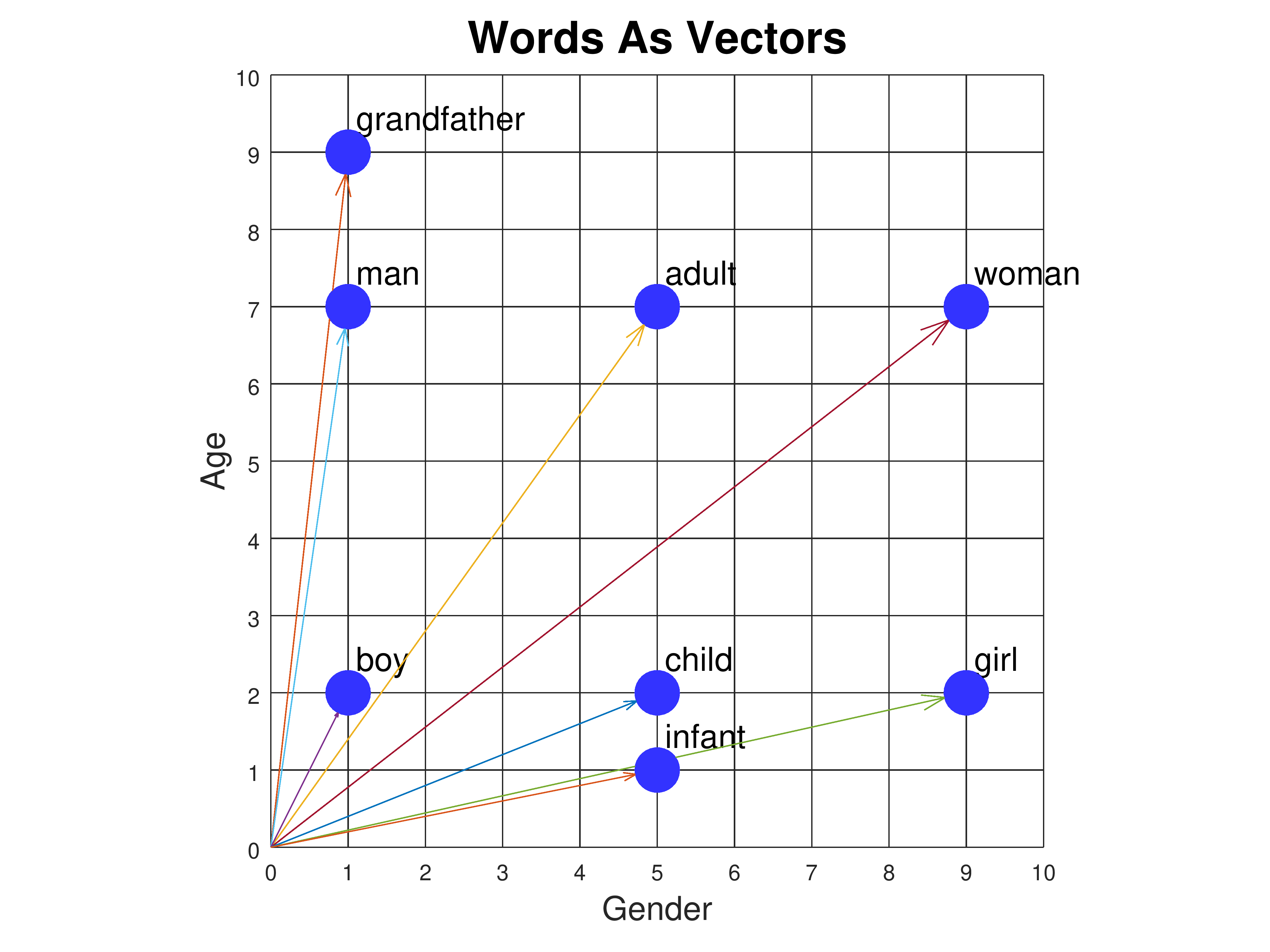
각 토큰의 벡터 표현은 단어의 의미를 담고 있어야 합니다. 유사한 의미를 가진 단어는 벡터 공간에서 가까운 위치에 있어야 합니다. 위 이미지는 시각적인 설명을 위해 Gender와 Age라는 두 축을 사용하여 단어 벡터를 2차원 공간에 표현하였으나, 실제 모델에서는 수백 차원 이상의 벡터 공간을 사용하며, 각 차원의 의미는 학습 과정에서 모델이 스스로 결정합니다.
과거에는 Word2Vec이나 GloVe와 같이 word embedding을 따로 학습시켜서 사용하기도 했으나, 최근 모델은 전체 LLM 아키텍처의 일부로 함께 학습시키는 추세입니다.
Encoder와 Decoder
자연어 처리 모델은 크게 Encoder와 Decoder로 구성됩니다.
Encoder는 토큰화된 텍스트의 word embedding 벡터들을 입력으로 받아, 이를 바탕으로 텍스트의 전반적인 의미를 담은 또 다른 벡터 표현인 hidden state를 만들어냅니다. Hidden state는 텍스트 전체 의미를 담은 단일 벡터로 표현될 수도 있고, 각 토큰에 맥락 정보를 담아 재구성된 벡터들의 집합으로 표현될 수도 있습니다.
Decoder는 새로운 텍스트를 생성하는 역할을 합니다. Encoder의 결과로부터 다음 토큰을 예측합니다. 예측된 토큰은 다시 Decoder의 입력으로 들어가며, Encoder의 결과 + 현재까지 예측된 토큰을 입력으로 받아 다음 토큰을 예측하는 과정을 반복합니다.
초기에는 Encoder와 Decoder가 하나의 모델로 구현되었으나, 이후에는 Encoder-only 모델과 Decoder-only 모델이 각각 독립적으로 발전하기도 했습니다.
순서 정보
자연어는 단어의 집합이 아니라 순서가 있는 시퀀스 데이터입니다.
The dog bit the man.
The man bit the dog.
두 문장은 같은 단어를 사용하지만, 순서가 바뀌면서 의미가 완전히 달라집니다. 따라서 자연어 처리 모델은 단어 자체뿐 아니라 단어의 순서를 반드시 고려해야 합니다.
문맥 의존성
자연어에서 한 단어의 의미는 주변 단어뿐 아니라 문장 전체, 심지어 문단 전체의 문맥에 의해 결정됩니다.
It is cold.
이 문장은 날씨를 말하는 것일 수도 있고, 음식이나 사람의 태도를 묘사하는 것일 수도 있습니다. 의미를 정확히 이해하려면 문맥 전체를 함께 고려하는 능력이 필요합니다.
모호성
자연어는 본질적으로 모호합니다. 하나의 단어가 여러 의미를 가질 수 있고, 하나의 문장이 여러 방식으로 해석될 수 있습니다.
자연어 처리는 이 모호성을 제거하는 것이 아니라, 상황에 따라 가장 그럴듯한 해석을 선택하는 것이 핵심입니다.
Transformer 이전 모델: RNN
RNN은 시퀀스 데이터를 처리하는 모델로, RNN 계열의 모델로는 Vanila RNN, LSTM, GRU 등이 있습니다. 자연어 역시 시퀀스 데이터이기에 초기 자연어 처리 모델로 RNN을 선택했습니다.
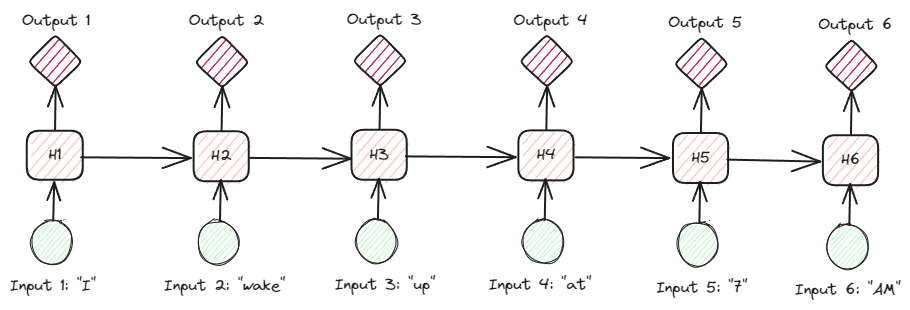
RNN은 이전 정보를 기억하면서 순차 데이터를 처리하는 모델입니다. 이를 위해 hidden state라는 것을 두어, 각 입력을 처리할 때마다 hidden state를 업데이트하고, 이를 기반으로 출력값을 계산합니다. $t$ 시점을 기준으로 입력값을 $x_t$, 출력값을 $y_t$, hidden state를 $h_t$로 두었을 때 다음과 같은 수식으로 표현할 수 있습니다.
$$ h_t = \phi (W_x x_t + W_h h_{t-1} + b_h) $$ $$ y_t = \psi (W_y h_t + b_y) $$
자연어 처리 RNN 모델은 각 토큰의 embedding vector를 입력으로 받으며, hidden state는 글의 맥락 정보라고 이해할 수 있습니다.
RNN의 한계점
그러나 RNN에는 구조적인 한계가 있습니다.
1. 긴 텍스트에서 맥락 정보를 잃어버린다.
Hidden state가 여러 차례 업데이트 되면서 중요한 정보가 시간이 지날수록 압축되거나 희석될 수 있습니다. 긴 텍스트일 경우 이 문제가 더욱 두드러지게 나타납니다. 비교적 개선된 LSTM에서 조차 한계가 있었습니다.
2. 순차 계산으로 인해 병렬화가 어렵다.
이전 시점의 hidden state를 알아야지만 다음 연산이 가능하기에, 병렬화가 어렵다는 특징이 있습니다.
Attention의 등장

Attention은 각 토큰 간의 정보 전달 방식을 바꾼 개념입니다. Attention의 핵심 아이디어는 각 토큰에 대해 다른 모든 토큰과 대조하여 “관련성”을 계산하고, 그 결과를 가중 합하여 해당 토큰의 표현을 다시 구성하는 것입니다. 즉, 다른 모든 토큰과의 관련성을 기반으로 어느 토큰에 더 “주목”할 것인가를 판단하는 메커니즘입니다.
두 토큰간의 “관련성”은 벡터의 내적으로 구현합니다.
$$ \vec{a} \cdot \vec{b} = \sum_{i=1}^{k} a_i b_i $$
벡터의 내적에는 다음과 같은 특징이 있습니다.
- 같은 방향이면 양수
- 직각이면 0
- 반대 방향이면 음수
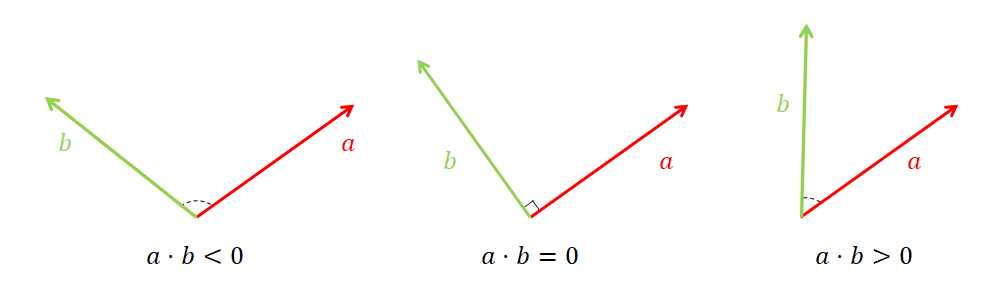
달리 말하면 내적은 벡터의 방향이 얼마나 비슷한지를 나타냅니다. 내적값이 크다면 두 단어 간의 관련성이 높다고 판단할 수 있습니다.
여러 벡터 간의 내적은 아래와 같이 하나의 행렬 곱으로도 표현할 수 있습니다.
$$ \begin{bmatrix} - & \vec{u_1}^T& - \\ - & \vec{u_2}^T & - \\ & \vdots & \\ - & \vec{u_m}^T & - \end{bmatrix} \begin{bmatrix} \vert & \vert & & \vert \\ \vec{v_1} & \vec{v_2} & \cdots & \vec{v_n} \\ \vert & \vert & & \vert \end{bmatrix} = \begin{bmatrix} \vec{u_1} \cdot \vec{v_1} & \vec{u_1} \cdot \vec{v_2} & \cdots & \vec{u_1} \cdot \vec{v_n} \\ \vec{u_2} \cdot \vec{v_1} & \vec{u_2} \cdot \vec{v_2} & \cdots & \vec{u_2} \cdot \vec{v_n} \\ \vdots & \vdots & \ddots & \vdots \\ \vec{u_m} \cdot \vec{v_1} & \vec{u_m} \cdot \vec{v_2} & \cdots & \vec{u_m} \cdot \vec{v_n} \end{bmatrix} $$
RNN과 Attention의 구조적 차이
RNN은 “단방향 독해”로, Attention은 “전역 참조”로 비유할 수 있습니다. RNN의 처리 방식은 마치 글을 읽을 때 한번 읽은 부분은 다시 되돌아보지 않는 것과 같습니다. 직전까지 읽은 내용의 맥락을 어느 정도는 기억할 수 있으나, 글이 길어질수록 맥락을 기억하는 데 한계가 있습니다.
반면에 Attention의 처리 방식은 현재 읽고 있는 부분을 이해하는 데 필요한 다른 부분을 참조하면서 읽는 것과 같습니다. 글의 다른 부분을 언제든지 참조할 수 있기 때문에 맥락의 “기억”에 의존할 필요가 없습니다.
연산량
RNN은 모든 토큰을 한 번씩 순차적으로만 처리하는 반면, Attention은 각 토큰이 다른 모든 토큰과 대조하기 때문에 연산량이 많아집니다. 시간복잡도로 표현하면 RNN은 $O(n)$, Attention은 $O(n^2)$이 됩니다.
병렬 처리
RNN은 한 입력값을 처리하기 위해서 이전 시점의 hidden state를 알아야 하므로 병렬 처리에 제약이 있습니다. 반면 Attention은 이러한 제약이 없어서 병렬 처리가 가능합니다.
순서의 의미
RNN은 순차 처리하며 정보를 전달하기에 자연스럽게 단어 순서의 의미를 학습하게 됩니다. 반면, Attention은 순서 개념이 없습니다. 따라서 초기의 Attention은 RNN 레이어 이후에 배치됨으로써 상호보완적 관계로 구현되었습니다.
RNN의 단점을 보완하기 위한 또 다른 방법으로 CNN이 제안되기도 했습니다. CNN은 병렬 처리가 가능하고, 지역적 패턴을 학습하는 데 강점이 있었으나, 긴 텍스트에서의 맥락 정보 학습에는 Attention보다 구조적으로 불리했습니다.
Transformer
2017년 Google이 발표한 「Attention is All You Need」 논문에서 Transformer 모델이 처음 제안됩니다. “Attention만 있으면 충분하다”라는 논문의 제목 그대로 Transformer는 RNN을 제거하고 Attention만으로 구성된 모델입니다.
Positional Encoding
앞서 언급했듯이 Attention에는 순서 개념이 없습니다. RNN을 제거한다면 다른 방식으로 순서의 의미를 주입할 필요가 있습니다. 여기에서 등장하는 것이 바로 positional encoding입니다.
Positional encoding 레이어는 word embedding 이후 Attention 이전에 위치하며, 각 토큰의 임베딩 벡터에 “위치 정보 벡터”를 더해줍니다. $t$ 번째 토큰의 임베딩 벡터 $e_t$, 위치 정보 벡터 $p_t$, Attention에 들어가는 최종 입력 $x_t$에 대해
$$ x_t = e_t + p_t $$
로 나타낼 수 있습니다. $p_t$를 어떻게 정의하는지에 따라 모델의 성질을 상당 부분 규정하기도 하며, 다양한 방식이 연구되어 왔습니다. 그중 일부 예시만 살펴보도록 하겠습니다.
Sinusoidal Positional Encoding
「Attention is All You Need」원논문에서 제안된 방식으로, sine과 cosine 함수를 사용합니다. $t$ 번째 토큰의 위치 정보 벡터 $p_t$의 $i$ 번째 원소를 $p_{t,i}$, 임베딩 벡터의 차원을 $d$로 두었을때
$$ \begin{aligned} p_{t,2i} = \sin \left( \frac{t}{10000^{2i/d}} \right) \\ p_{t,2i+1} = \cos \left( \frac{t}{10000^{2i/d}} \right) \end{aligned} $$
로 표현될 수 있습니다.
Learned Positional Encoding
Learned Positional Encoding은 $p_t$를 학습 가능한 파라미터 벡터로 둡니다. 토큰 위치별 벡터를 lookup 하는 방식으로 구현하며, $최대토큰길이 \times 벡터차원$ 만큼의 학습 파라미터를 갖습니다.
Attention
「Attention is All You Need」 논문은 이전에 언급되었던 Attention 개념을 Query, Key, Value 구조로 더욱 체계화했습니다.
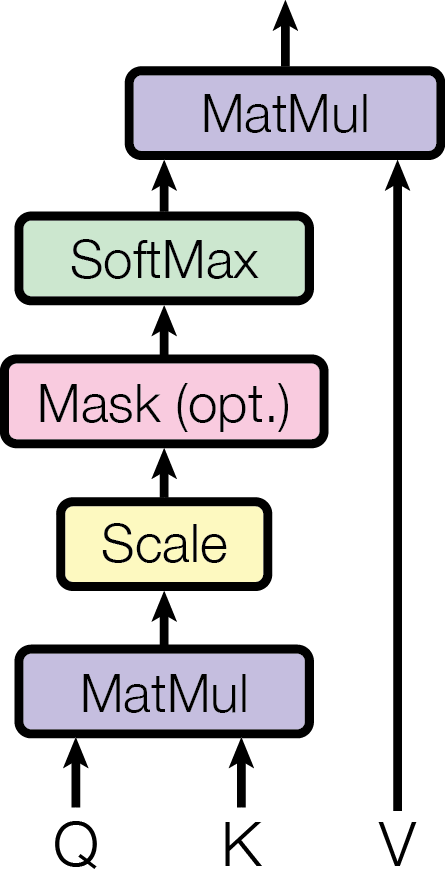
Query, Key, Value의 의미는 다음과 같습니다.
- Query: “지금 내가 찾고 있는 의미는 무엇인가”
- Key: “각 토큰이 어떤 의미를 가지는가”
- Value: “그 토큰이 실제로 제공하는 내용”
Positional encoding을 거친 최종 임베딩 벡터에 linear projection으로 각각 Query, Key, Value를 만듭니다. 임베딩 벡터를 모아놓은 행렬 $X$에 대해 다음과 같이 표현할 수 있습니다.
$$ \begin{aligned} Q = XW_q + b_q \\ K = XW_k + b_k \\ V = XW_v + b_v \end{aligned} $$
Query와 key는 서로 내적하여 “관련성” 정보를 구하고, 이 내적 결과에 따라 Value를 가중합합니다.
$$ Attention(Q,K,V) = Softmax \left( \frac{QK^T}{\sqrt{d_k}} \right) V $$
Self-Attention과 Cross-Attention
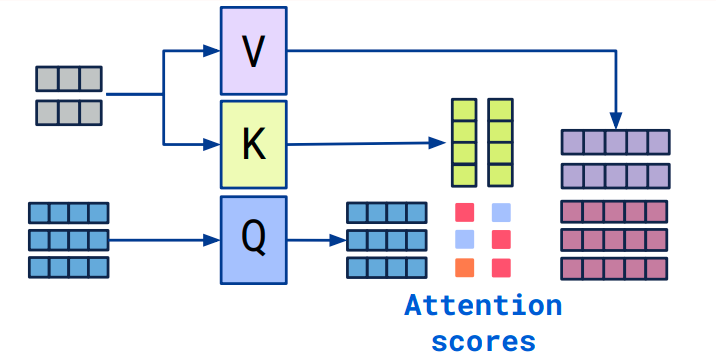
지금까지는 Self-Attention에 기반하여 설명해 왔습니다. Self-Attention은 동일한 텍스트 내에서 토큰 간의 관련성을 계산하는 방식입니다. 그러나 한 텍스트가 다른 텍스트를 참조해야 하는 경우도 있습니다. Encoder-Decoder 구조에서 Decoder가 Encoder의 출력을 참조해야 하는 경우가 대표적입니다.
이때 사용되는 것이 Cross-Attention입니다. Cross-Attention의 구현 방식은 Self-Attention과 유사하되, Query는 Decoder의 토큰에서 나오고, Key와 Value는 Encoder의 토큰에서 나옵니다.
Multi-Head Attention
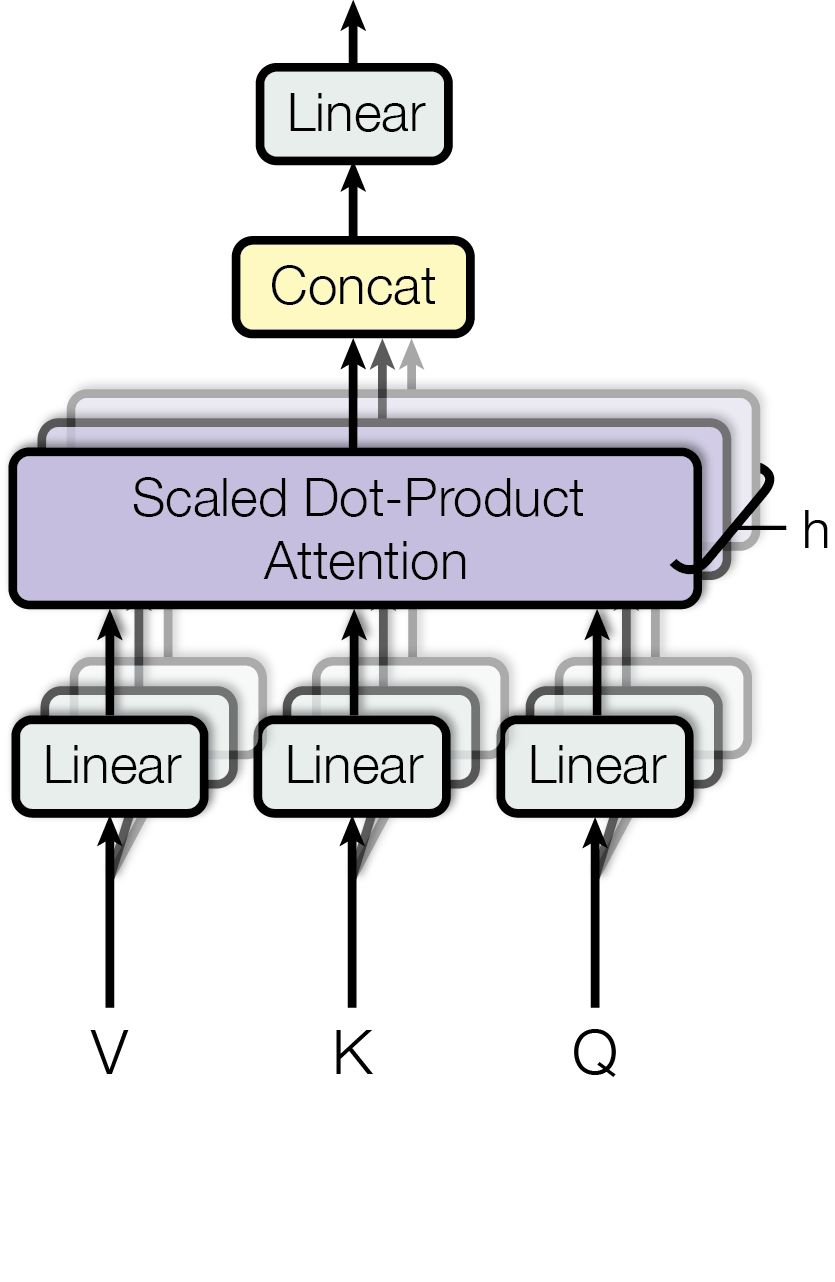
하나의 Attention이 아니라 여러 개의 Attention을 병렬로 구성할 수 있으며, 이를 Multi-Head Attention이라고 부릅니다. 각 Attention이 서로 다른 방식으로 관련성을 계산하기 때문에, 모델이 다양한 관점에서 단어 간의 관계를 학습할 수 있게 됩니다. 앞서 자연어 처리 모델의 핵심 요소에서 언급한 “모호성”을 학습하는 데도 도움이 됩니다.
Transformer가 가져온 변화
Transformer의 등장은 단순히 새로운 모델 구조를 제안했다는 것 그 이상의 전환점이 되었습니다.
순차적 연산에 묶여 있던 학습 구조를 병렬화 가능한 형태로 바꿔놓음으로써, 모델 성능이 스케일 확장을 통해 개선될 수 있다는 것을 보여주었습니다. 이후 LLM 분야는 더 좋은 아키텍처를 찾는 경쟁에서 더 큰 모델을 만드는 경쟁으로 넘어갔습니다. 이에 따라 GPU, TPU, HBM 메모리와 같은 고성능 반도체 수요를 폭발적으로 증가시켰고, 대형 데이터센터의 전력 소비 또한 크게 늘어났습니다. 반도체 산업과 에너지 산업에까지 영향을 미친 셈입니다.
또한 Transformer는 더 이상 자연어 처리에만 머물러 있지 않습니다. 비전 분야에서는 CNN 중심 구조를 대체하는 Vision Transformer가 등장하는 등 다양한 분야로 확장되고 있습니다.



댓글남기기