Black Box Problem과 XAI (feat. GradCAM)
저는 인공지능을 통해 코딩을 시작하게 되었습니다. 수학전공자로 인공지능 수학 수업을 들으며 Python을 사용하게 되었고, 본격적으로 개발자의 길을 가기로 결심하게 되었기 때문입니다. 그중에서도 XAI는 수업에서 발표주제로 삼았던 내용이기도 합니다. 이번 포스팅에서는 당시 발표했던 내용을 공유합니다.
통계 분석 vs 인공지능
통계 분석은 인과관계에 중점을 둡니다. 인과관계를 통해 모델을 도출하고, 이후에 데이터로 모델을 검증합니다.
반면에 인공지능은 인과관계보다 상관관계에 중점을 둡니다. 데이터 샘플에서 패턴을 학습하여 모델을 도출하고, 또 다른 데이터 샘플로 검증합니다.
데이터에 의해 학습되는 인공지능은 통계 분석과 비교하여 훨씬 많은 패턴을 학습할 수 있습니다. 때로는 그 패턴을 사람이 이해하기 어려울 정도로 복잡한 패턴일 수도 있죠. 이는 인공지능의 장점이자 우려되는 부분이기도 합니다. 상관관게 중심의 모델로 잘못된 인과관계를 추정하는 오류를 범할 수 있기 때문입니다. 따라서 아무리 정확도가 높은 인공지능 모델이라 할지라도 내부 처리 방식을 분석할 필요가 있습니다.
Black Box Problem이란
Black Box 모델이란 입력과 출력 및 수행 기능은 명확하나, 내부 처리 방식은 사람이 이해하기 어려울 정도로 복잡한 모델을 말합니다.

인공지능 모델에 있어서 내부 처리 방식은 학습된 파라미터들의 의미를 파악함으로써 이해할 수 있습니다. 일차함수와 같이 간단한 모델은 계수의 의미가 직관적으로 보이지만 위와 같은 neural network 모델에서 각각의 파라미터가 같는 의미를 일일이 파악하는 것은 사람의 능력으로는 불가능에 가깝습니다.


정확도가 높은 모델이라도 잘못된 인과관계를 학습할 수 있습니다. 위의 사진은 허스키와 늑대를 구분하는 인공지능입니다. 보시다시피 하나의 경우만 제외하고 전부 잘 예측을 하고있어서 정확도가 높은 모델이라고 할 수 있습니다.

그러나 실제 이 모델의 판단 근거를 Lime 알고리즘으로 시각화해서 나타내면 위와 같습니다. 동물의 특징보다는 배경을 보고 판단한 흔적들이 보이죠. 결코 좋은 모델이라고 볼 수 없습니다.
Black Box 모델의 잠재적 위험성
사람의 능력으로 이해하기 어려운 인공지능을 검증 없이 활용하는 것에는 큰 위험이 따를 수 있습니다.

2018년도에는 우버 자율주행 시험 중 보행자를 감지하지 못하여 사망에 이르게 한 사건이 있었습니다. 물론 해당 사건은 작업자가 주행 중 시스템을 관찰하지 않고 핸드폰을 보는 행위를 하여 직무 태만으로 결론이 났지만, 보행자를 보고 멈추지 않았던 인공지능의 판단 또한 분석할 필요가 있었을 것입니다.

인공지능의 내부 처리 방식을 이용한 공격 또한 가능하죠. 사람의 눈으로는 구분되지 않는 노이즈를 이미지에 더해 인공지능의 판단을 완전히 바꿀 수 있습니다. 이러한 방식으로 생성된 이미지를 적대적 예제라고 합니다.
자율주행, 의학 진단, 신용등급 결정, 채용 등 여러 분야에서 인공지능 모델이 도입되고 있습니다. 삶에 직접적인 영향을 주는 영역에서 활용되는 인공지능 모델에 취약점이 가득하다면 상당이 위험할 수 있겠죠. 따라서 인공지능의 판단에 대한 분석이 필요합니다.
Explainable Artificial Intelligence (XAI) 의 등장
XAI는 AI가 내린 결정을 사람이 이해하는 형태로 설명하고 제시할 수 있는 기술을 말합니다. 데이터의 각 속성이 AI의 결정에 기여하는 정도를 수치화하여 시각화하는 것이 일반적인 방법입니다.
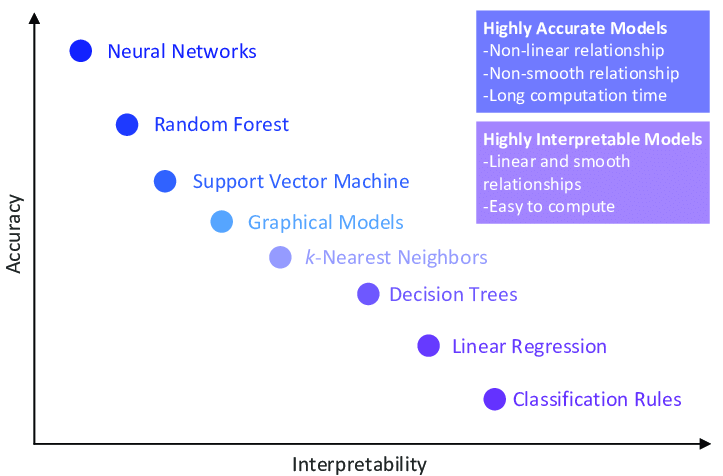
인공지능의 판단을 분석하는 데에는 데이터와 모델의 유형에 따라 여러 기법들이 존재합니다. 일반적으로 정확도가 높은 모델일수록 직관적인 해석이 어려우며, 그 만큼 XAI 기법을 필요로 합니다.
오늘은 XAI의 여러 예시 중 GradCAM을 살펴보겠습니다.
GradCAM
GradCAM은 이미지 데이터의 대표적인 인공신경망 모델인 Convolutional Neural Network (CNN)의 판단 근거를 시각화하기 위한 모델입니다.
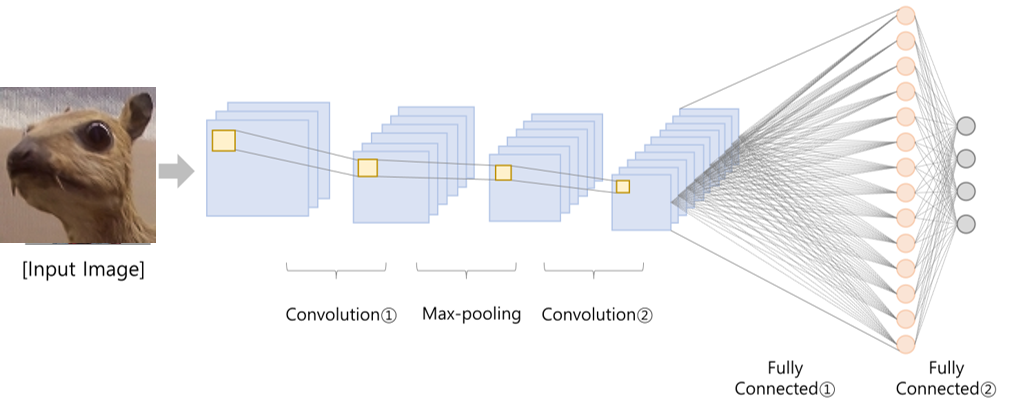
CNN에는 이미지의 특징을 살려내기 위한 convolutional layer와 분류를 위한 fully connected layer로 구성되어 있습니다. 각 convolutional layer에서는 filter의 합성곱을 통해 feature map이 생성됩니다.
GradCAM은 마지막 convolutional layer의 각 feature map이 결과에 영향을 미친 정도를 파악합니다. 이는 input에서부터 마지막 convolutional layer까지의 순전파와 output에서부터 마지막 convolutional layer까지의 역전파의 곱을 통해 구해집니다. 즉, feature map과 gradient의 곱으로 이뤄집니다. 계산이 완료된 모든 feature map을 더하고 ReLU로 양의 가중치만 골라내면 초기 입력 이미지의 어느 부분이 판단에 영향을 미쳤는지를 수치화할 수 있습니다. 이를 다시 heatmap으로 시각화 또한 가능합니다.

저는 tf-explain 라이브러리로 GradCAM heatmap을 생성해봤습니다. tf-explain은 Sicara라고 하는 프랑스 파리의 한 기업에서 개발된 라이브러리로 GradCAM을 포함한 여러 이미지 기반 XAI 기법을 제공합니다. 관련 소스는 아래 링크에서 확인하실 수 있습니다.
https://github.com/juhonamnam/data-analysis/blob/main/xai/xai.ipynb



댓글남기기