실시간 서비스 환경을 위한 신체 분할 기반 인물 재식별(Re-ID) 모델 개발기
실제 서비스 환경에서 작동하는 실시간 인물 재식별(Person Re-Identification, Re-ID) 시스템을 개발했던 경험을 공유합니다. 가림(Occlusion)이나 잘림(Cropping)이 빈번한 실제 CCTV 환경에서 속도, 정확도, 그리고 커버리지(Coverage) 사이의 트레이드오프를 해결하기 위해 내린 엔지니어링적 의사결정과 모델 경량화 과정을 정리했습니다.
1. 들어가며: Real-time Re-ID의 난제들
인물 재식별(Person Re-Identification, Re-ID)은 서로 다른 카메라 뷰나 시간대에서 포착된 인물 이미지를 비교하여 동일인 여부를 판별하는 기술입니다. 스마트 관제, 고객 동선 추적 등 다양한 도메인에서 핵심 기술로 활용되지만, 학계의 벤치마크 데이터셋과 달리 실제 서비스 환경에서는 다음과 같은 실질적인 문제들에 부딪히게 됩니다.
- 가림(Occlusion) 및 잘림(Cropping) 현상: 사람이 다른 물체에 가려지거나, 객체 탐지(Object Detection) 단계에서 신체의 일부만 크롭되어 들어오는 경우가 매우 많습니다.
- 실시간성(Real-time) 요구: 실시간 관제를 위해서는 대량의 CCTV 스트림에서 초당 수십 프레임의 속도로 인물을 탐지하고 매칭해야 합니다.
- 대규모 매칭 속도: 다수의 카메라에서 수집되는 수많은 인물 임베딩 벡터 사이에서 가장 유사한 대상을 찾아내는 매칭 연산이 병목이 되기 쉽습니다.
이러한 문제들을 해결하기 위해 신체 부위 분할 정보를 활용하는 BPBReID(Body-Part-Based Re-ID) 기법에 주목하였고, 이를 실제 실시간 서비스가 가능하도록 경량화 및 최적화하여 realtime-re-id 프로젝트를 개발하게 되었습니다.
2. 핵심 아이디어: 속도, 정확도, 그리고 커버리지(Coverage)
학계의 모델들은 대개 정확도(mAP, Rank-1)를 높이기 위해 크고 무거운 백본 네트워크를 사용하지만, 실제 서비스에서는 “속도”와 “커버리지” 역시 매우 중요합니다.
여기서 커버리지(Coverage)란 전체 탐지된 Bounding Box 중에서 모델이 Re-ID 연산을 수행하기에 충분한 품질을 갖추었다고 판단하여 필터링을 통과시킨 비율을 의미합니다.
- 엄격한 필터링: 정확도는 올라가지만, 조금만 몸이 가려져도 매칭을 포기하므로 커버리지가 낮아져 실용성이 떨어집니다.
- 느슨한 필터링: 커버리지는 높아지지만, 노이즈가 섞인 이미지나 엉뚱한 물체까지 매칭을 시도하게 되어 정확도가 급격히 하락합니다.
따라서 이번 프로젝트에서는 속도(Speed), 정확도(Accuracy), 커버리지(Coverage)의 3자 트레이드오프를 최적화하는 것을 목표로 설정했습니다.
3. 모델 아키텍처 및 엔지니어링적 의사결정
실시간 Re-ID 파이프라인의 전체적인 아키텍처는 아래와 같이 구성됩니다.
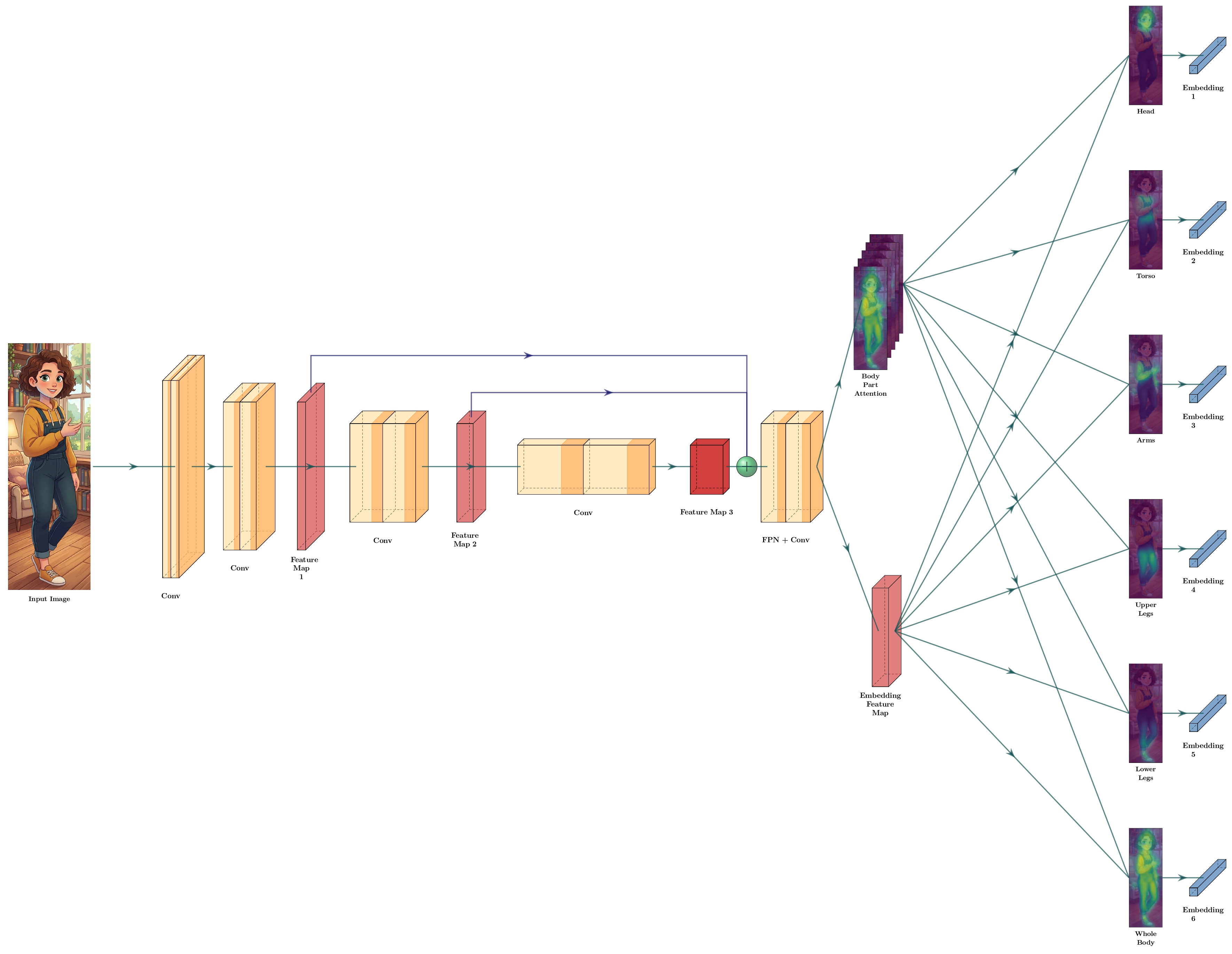
1) 경량 백본으로의 전환: HRNet에서 MobileNetV3 + FPN으로
원래 BPBReID 논문에서는 고해상도 세그멘테이션 성능이 뛰어난 HRNet을 백본으로 사용해 높은 정확도를 달성했습니다. 하지만 HRNet은 연산량이 너무 많아 실시간 카메라 스트림을 처리하기에는 부적합했습니다.
이를 극복하기 위해 저사양 기기에서도 빠르게 동작하는 MobileNetV3를 백본으로 실험했습니다. 다만, MobileNetV3 단독으로는 세그멘테이션에 필요한 고해상도 피처 맵을 보존하기 어렵기 때문에, FPN (Feature Pyramid Network) 구조를 추가로 결합했습니다. 이를 통해 속도를 4배 이상 향상시키면서도 고해상도 세그멘테이션 성능을 어느 정도 유지할 수 있었습니다.
2) 신체 부위 분할 방식의 재설계
품질 필터링(Quality Filtering)에서는 사전에 지정한 신체 부위가 모두 보이는 상태인 바운딩 박스만 최종 매칭에 사용합니다. 어떤 신체 부위를 기준으로 삼을지에 대해 두 가지 안을 두고 실험했습니다.
- 5pf (5-part Segmentation + Foreground Mask): 머리(Head), 몸통(Torso), 팔(Arms), 허벅지(Upper Legs), 종아리·발(Lower Legs)
- 5paf (Alternative 5-part): 머리(Head), 몸통(Torso), 팔(Arms), 다리(Legs), 발(Feet)
실험 결과, 발(Feet)은 CCTV 화면 아래쪽으로 잘리거나 땅에 닿아 가려지는 일이 매우 흔했습니다. 또한 발은 신체의 다른 부위에 비해 상대적으로 작은 영역을 차지하기 때문에, MobileNetV3와 같은 경량 백본에서는 발을 정확히 학습하지 못하는 경우가 많았습니다. 따라서 5paf 구조를 채택할 경우 유효 박스로 판단하고 통과되는 커버리지가 극단적으로 낮아지는 현상이 발생했습니다. 실서비스 적합성을 위해 종아리와 발을 한 부위로 묶은 5pf 방식을 기본 세그멘테이션 규격으로 최종 채택했습니다.
3) 매칭 방식의 최적화: 단일 고정 벡터 병합과 ANN 도입
원래 BPBReID 모델은 두 이미지 사이의 거리를 계산할 때, 양쪽 이미지에서 공통으로 가시성이 확보된 신체 부위의 임베딩 벡터들만 선택적으로 L2 Distance를 구하는 가변 매칭 방식을 사용합니다. 즉, 일부 부위가 가려지더라도 나머지 부위만으로 매칭을 수행할 수 있는 유연한 구조입니다.
하지만 이러한 가변적 매칭은 유연할 수 있어도 데이터베이스에 저장된 수많은 인물들과 실시간으로 매칭 연산을 수행할 때 심각한 병목을 유발합니다. 비교할 때마다 벡터 차원이나 결합 방식이 달라지기 때문입니다.
우리는 앞 단계의 Quality Filtering을 통해 모든 신체 부위(5개 파트)가 무조건 검출된 안정적인 바운딩 박스만 사용하도록 강제했습니다. 덕분에 5개 부위의 임베딩 벡터를 순서대로 이어 붙여(Concatenate) 하나의 단일 고정 크기 임베딩 벡터로 다룰 수 있게 되었습니다.
하나의 고정 길이 벡터를 사용하게 됨으로써 얻는 엔지니어링적 이점은 엄청납니다. 바로 ANN (Approximate Nearest Neighbor) 검색 알고리즘(예: FAISS, Annoy 등)을 적용할 수 있게 되어, 수천~수만 명의 데이터베이스 안에서도 실시간(Sub-millisecond) 단위로 가장 유사한 인물을 초고속 매칭할 수 있게 된 것입니다.
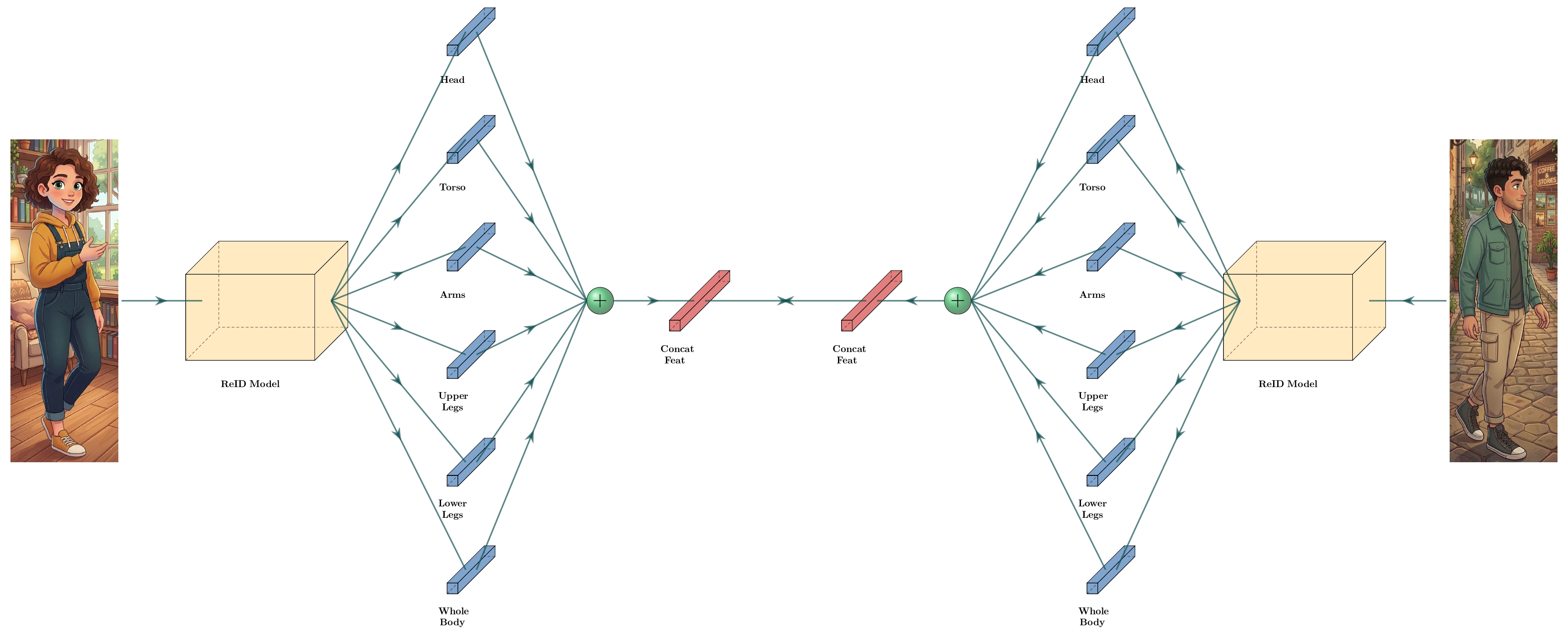
4. Multi-task 학습 전략
재식별 임베딩 학습과 신체 분할 학습이 동시에 이루어져야 하므로 Multi-task Learning 방식으로 학습을 진행했습니다.
- Segmentation Head: COCO DensePose 데이터셋을 활용해 신체 부위를 분할하도록 학습시켰으며, 클래스 불균형 문제를 해결하기 위해 Focal Loss를 적용했습니다.
- Feature Extraction Head: Market1501, DukeMTMC-reID, AI Hub의 한국인 재식별 이미지 데이터셋을 함께 활용하여 Classification Loss와 Triplet Loss를 혼합하여 학습시켰습니다.
특히 서로 다른 도메인의 데이터셋을 통합하여 학습할 때 모델의 일반화(Generalization) 성능을 높이기 위해, 배치 단위에서 데이터셋이 섞이지 않도록 분리하고, 학습 시 각 데이터셋 고유의 Classification Layer를 개별적으로 연결해 학습을 진행했습니다. 이를 통해 서로 다른 도메인 데이터 간 불필요한 레이블 노이즈(Label Noise)가 발생하는 문제를 방지할 수 있었습니다.
5. 정량적 평가 결과 (Market1501 벤치마크)
다양한 실험 조건 속에서 측정된 핵심 지표들은 다음과 같습니다.
| Backbone | Segment Variant | mAP (%) | Rank-1 (%) | Coverage (%) | Speedup (vs HRNet) |
|---|---|---|---|---|---|
| HRNet | 5pf | 76.7 | 91.0 | 91.4 | 1.0 x (Base) |
| MobileNetV3 Large + FPN | 5pf | 63.6 | 82.9 | 91.0 | 4.02 x |
| MobileNetV3 Small + FPN | 5pf | 51.6 | 73.6 | 80.2 | 4.31 x |
| HRNet | 5paf | 79.8 | 91.5 | 71.2 | 1.0 x |
| MobileNetV3 Large + FPN | 5paf | 66.7 | 81.7 | 56.7 | 4.02 x |
| MobileNetV3 Small + FPN | 5paf | 61.8 | 73.0 | 25.4 | 4.31 x |
- HRNet vs MobileNetV3: MobileNetV3 Large 백본을 적용했을 때 mAP는 일부 하락했으나, 인퍼런스 속도가 4배 이상 향상되어 실시간 관제에 적합한 성능을 보여주었습니다.
- 5pf vs 5paf (커버리지 붕괴): 발(Feet) 검출 여부가 포함된
5paf구조는 MobileNetV3 Small 환경에서 커버리지가 25.4%까지 곤두박질쳤습니다. 이는 촬영된 인물 4명 중 3명은 Re-ID 처리를 아예 시도조차 못 하고 버려짐을 의미합니다. 반면5pf방식은 91.0%의 높은 커버리지를 안정적으로 보장했습니다.
6. 브라우저에서 작동하는 100% On-device 웹 데모
개발한 모델의 실시간 작동을 시각적으로 보여주기 위해 ONNX 포맷으로 변환한 후, onnxruntime-web을 이용해 웹캠 기반의 라이브 데모 페이지를 구축했습니다.
서버를 거치지 않고 웹 브라우저 내부에서 사용자의 CPU/GPU 자원만으로 실시간 객체 검출(YOLO) 및 Re-ID 모델 피드포워드가 모두 완결되도록 구현했습니다.
사용 방법:
- 웹캠 화면에서 인물들이 탐지되면 스냅샷(Snapshot)을 촬영합니다.
- 검출된 인물 중 한 명을 클릭하여 추적 대상(Target)으로 설정합니다.
- 이후 라이브 피드에서 모델이 실시간으로 대상을 식별합니다.
- 빨간색 박스: 타겟 인물로 매칭됨
- 노란색 박스: 타겟과 다른 인물로 식별됨
- 회색 박스: 가림/잘림이 심해 Re-ID 대상에서 제외된 인물 (Quality Filtered)
7. 마치며
이번 프로젝트는 학계의 고성능 아키텍처를 그대로 가져다 쓰는 것에 그치지 않고, 실제 서비스 환경에서 부딪히는 제약 조건(속도, 네트워크 환경, 가림 현상)들을 정의하고 이를 해결하기 위해 아키텍처를 변형하고 최적화해 본 뜻깊은 경험이었습니다.
특히 정확도를 약간 양보하더라도 품질 필터링 설계를 다듬어 실용적인 커버리지를 확보하고, 단일 임베딩 벡터 병합을 통해 ANN 라이브러리 도입의 확장성을 마련한 점은 실제 인프로 구축 단계에서 큰 빛을 발했던 핵심 엔지니어링 의사결정이었습니다.
이러한 접근법이 실시간 비디오 분석 및 멀티 카메라 트래킹 시스템을 준비하는 다른 엔지니어분들께도 도움이 되기를 바랍니다. 소스 코드가 궁금하신 분들은 아래 GitHub 리포지토리를 참고해 주세요!



댓글남기기